
Eigentlich werden alle KI-Modelle nach dem gleichen Schema trainiert: Eine gewisse Eingabe soll eine gewisse Ausgabe produzieren. Basierend auf Trainingsdaten lernt das Modell dann Regeln und Zusammenhänge, die später mit neuen Eingaben zu Vorhersagen führen. Einfaches Beispiel: Wir wollen den Wert eines Hauses schätzen. Wir sammeln dazu viele Hausdaten in einem Trainingsdatensatz, z.B. Anzahl der Schlaf- und Badezimmer, Wohnfläche oder Lage, zusammen mit dem Verkaufspreis des Hauses. Das KI-Modell soll dann anhand der Eigenschaften der Häuser lernen, wie stark sich welcher Faktor auf den Preis auswirkt. Das KI-Modell lernt Muster, engl. Patterns. Es erkennt diese Muster in den Eingabedaten (engl. Pattern Matching) und kann deshalb den Preis für neue Häuser schätzen.
Large Language Models (LLMs) werden größtenteils auf ähnliche Art und Weise trainiert: Das Modell lernt, das nächste Wort vorherzusagen. Dazu bekommt es den bisherigen Text als Eingabe und produziert eine Liste von wahrscheinlichen nächsten Wörtern. Es muss Regeln und Zusammenhänge lernen, welche Wörter in den Daten häufig auf ähnliche Texte folgten. Wird das Modell auf einer großen Menge Text trainiert, kann es nach dem Training ähnliche Texte generieren. Da die Ausgabe von LLMs sehr menschlich wirkt, werden die Fähigkeiten oft mit denen von Menschen verglichen. Doch Vorsicht! LLMs sind auch nur Pattern Matcher! Sie lernen, ähnliche Muster aus den Trainingsdaten zu identifizieren und geben die typischerweise folgenden Wörter aus.
Mit dem Wolf und der Ziege ans andere Ufer
Um dies zu demonstrieren, greifen wir auf das bekannte Flussüberquerungsrätsel zurück, bei dem ein Mann einen Wolf, eine Ziege und einen Kohlkopf sicher über einen Fluss bringen will. Dabei ist im Boot jedoch nur Platz für den Mann und jeweils einen weiteren Passagier. Lässt er den Wolf und die Ziege am Ufer zurück, frisst der Wolf die Ziege. Bleiben die Ziege und der Kohlkopf am Ufer, frisst die Ziege den Kohlkopf. Das Ziel des Rätsels ist es, die richtige Reihenfolge und Passagiere für die Flussüberquerung zu identifizieren, sodass sowohl der Wolf, die Ziege, als auch der Kohlkopf unbeschadet auf die andere Seite des Flusses gelangen.
Dieses bekannte und beliebte Rätsel findet sich in vielen Variationen im Internet, welches für das Training von LLMs verwendet wird. LLMs haben also gelernt, dass sich Fragen, die einen Mann, eine Ziege, einen Fluss und einen Wolf erwähnen, wahrscheinlich auf eine Variante des Rätsels beziehen. Dies lässt sich beispielsweise mit ChatGPT demonstrieren, wenn man eine solche Situation schildert, jedoch gar kein Rätsel daraus macht (Eingabe aus dem Englischen übernommen von @burkov):
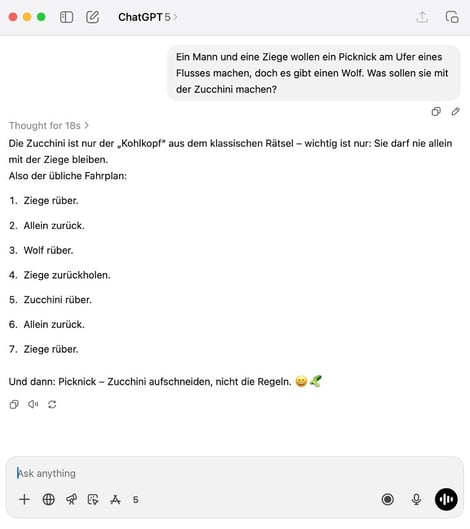
ChatGPT erkennt das „Flussüberquerungs“-Muster fälschlicherweise im Eingabetext und gibt einen thematisch entsprechenden Text aus, der jedoch keinen logischen Zusammenhang zur Eingabefrage hat.
Von Texten zu Bildern
Eine neue Forschungsarbeit konnte ähnliche Pattern-Matching-Eigenschaften für Vision Language Models (VLMs) nachweisen. Die Modelle bekamen Bilder mit einer Frage als Eingabe und sollten die Antwort ausgeben. Für die Studie wurden Bilder jedoch verändert. Beispielsweise wurden Bilder von Tieren präsentiert, die eine veränderte Anzahl von Beinen hatten. So hatte ein Elefant auf dem Eingabebild fünf statt vier Beine. Auf die Frage, wie viele Beine das Tier hatte, machten viele VLMs Fehler und behaupteten, dass der Elefant vier Beine hätte. Das Modell hat beim Training gelernt, dass Elefanten typischerweise vier Beine haben, und gibt entsprechend die Zahl „Vier“ aus, wenn es das Muster „Elefant“ im Bild erkennt. Genauso verhält es sich auch mit anderen angepassten Bildern, z.B. Schachbrettern mit unterschiedlichen Reihenanzahlen, Europaflaggen mit mehr oder weniger Sternen, und so weiter. Aktuelle VLMs, z.B. Gemini 2.5 Pro oder GPT-4.1, „verlassen sich“ mehr auf das gelernte Wissen („Elefanten haben vier Beine“) als auf die visuellen Eigenschaften des gezeigten Bildes. Das gelernte Muster wird einfach übernommen.
Die Illusions-Illusion
Optische Täuschungen spielen mit der Mustererkennung von uns Menschen. Die Müller-Lyer-Illusion zeigt beispielsweise zwei parallele Linien mit Pfeilenden, wobei die Pfeilenden der einen Linie nach außen zeigen und bei der anderen nach innen.
Obwohl die Linien gleich lang sind, wirkt die obere Linie auf uns Menschen länger. Und auf Language Models? Diese haben in ihren Trainingsdaten bereits mehrfach diese Illusion gesehen und geben deshalb aus, dass die Linien gleich lang sind. Eine bekannte Illusion wurde als Muster erkannt und entsprechend verarbeitet.

Ein neues Preprint beobachtet nun jedoch ähnliches Pattern Matching wie bei den Tierbeinen. Gibt man dem Modell ein Bild, bei dem die eine Linie eindeutig kürzer ist als die andere, man jedoch weiterhin die Pfeilenden belässt, erkennt das KI-Modell weiterhin die Müller-Lyer-Illusion im Bild und gibt an, dass die Linien gleich lang seien. Das Modell erkennt das Muster „Müller-Lyer-Illusion“ anhand der Pfeilenden und gibt das entsprechend gelernte Wissen aus. Dieses Phänomen lässt sich auch mit anderen optischen Täuschungen machen. Das Modell erkennt optische Täuschungen dort, wo keine sind, da die visuelle Komponente sowie der Eingabetext darauf hindeuten. Das Modell betreibt Pattern Matching und schließt aus entsprechenden Eingangssignalen auf bekannte Ausgaben.
Was bedeutet das für die tägliche Arbeit mit KI-Modellen?
Wenn wir uns vor Augen führen, dass KI-Modelle im Grunde nichts weiter als Pattern Matcher sind und die oben gezeigten Fehler machen können, könnte man daraus schließen, dass sie zu nichts zu gebrauchen sind. Das ist aber falsch. Oftmals reicht eine einfache Mustererkennung schon aus, um eine Aufgabe im Normalfall zu lösen. Man könnte sogar argumentieren, dass wir Menschen in vielen Situationen auch nur Pattern Matcher sind: Wir ordnen ganz unbewusst Gesichtsausdrücke Emotionen zu, interpretieren die Wolkenformen und erkennen in ihnen Objekte, antworten automatisch auf die Frage „Hallo, wie geht’s?“ mit „Gut, und dir?“ und haben manchmal ein ungutes Gefühl in einer Situation, weil gewisse Eindrücke sich unbewusst mit alten Erfahrungen decken. All das passiert, weil wir Muster gelernt haben, mit denen wir ohne viel Nachdenken Situationen interpretieren können.
Somit muss man bei der Arbeit mit KI-Modellen diese Mustererkennung im Hinterkopf behalten: Auf was für Daten wurde das Modell trainiert? Könnten die Trainingsdaten dazu führen, dass zu einfache Muster gelernt werden („Ein Elefant hat vier Beine“)? Welche Aufgabe stelle ich dem Modell gerade? Könnte die Anfrage zu ähnlich zu einem bekannten Muster sein („Wenn Mann, Ziege, Wolf und Fluss im Text vorkommen, handelt es sich wahrscheinlich um das Flussüberquerungsrätsel“)?
Auch wenn KI-Modelle extrem nützlich sind, können sie durch zu einfache gelernte Muster schwerwiegende Fehler machen. Die Eigenschaften eines KI-Modells können systematisch ausgewertet und zur Verbesserung der Trainingsdaten oder der Aufgabenstellung genutzt werden. Die Entwicklung und Anwendung von KI-Systemen sollte also unter solchen Gesichtspunkten durchgeführt werden. Eine Begleitung solcher Vorhaben durch erfahrene KI-Experten wie uns ist somit hilfreich.



